Topic outline
-
Glosario
-
El sesgo de muestreo o una muestra sesgada en investigación se produce cuando los miembros de la población prevista se seleccionan de forma incorrecta, ya sea porque tienen una probabilidad menor o mayor de ser seleccionados. Hay muchas causas de sesgo en el muestreo que los investigadores deben tener en cuenta. Éstas son las más comunes: la infra cobertura es una de las principales causas del sesgo de muestreo, ya que los investigadores no consiguen representar con exactitud la muestra. La principal razón de esta infra cobertura es la representación inadecuada de la población o la recogida de respuestas sólo de encuestados fácilmente disponibles mediante el uso de un método de muestreo adecuado.Una vez que se asigna una columna a una estética de la gráfica (por ejemplo, x =, y =, fill =, color =…), la gráfica ganará una escala. Las escalas pueden ser continuas, discretas, de fecha, etc., dependiendo del tipo de columna asignada. Si hay múltiples estéticas asignadas a las columnas, el gráfico tendrá múltiples escalas.Un cuantil es aquel punto que divide la función de distribución de una variable en intervalos regulares. Por tanto, no es más que una técnica estadística para separar los datos de una distribución. Eso sí, debe cumplirse que los grupos sean iguales. Por eso, existen diversos tipos de cuantil, en función del número de particiones que hacen. Son de enorme utilidad en muchas aplicaciones prácticas estadísticas.
-
La Gestalt, en psicología, es una corriente que estudia cómo percibimos el mundo, enfocándose en cómo la mente organiza la información visual y sensorial en patrones significativos. En lugar de ver elementos aislados, la Gestalt enfatiza que percibimos el todo como algo más que la suma de sus partes.La asociación espuria en el modelo de regresión lineal ocurre cuando la variable independiente contribuye a explicar de manera importante la variabilidad de la variable respuesta de acuerdo con la prueba de hipótesis sobre el parámetro de la variable independiente, a pesar de que ambas variables no tienen ninguna relación.
-
Se define como la unión de A y B, que se escribe A ∪ B y se lee "A unión B", consta de tales elementos que están en A, en B o en ambos. Por ejemplo, todos los estudiantes que están en la clase (conjunto A), sin tener en cuenta su especialización, y todos los especialistas en economía (conjunto B), son elementos de A ∪ B.
Se define como la intersección de A y B, que se escribe A ∩ B y se lee "A intersección B", y consta de elementos que están en ambos conjuntos simultáneamente.La probabilidad condicionada es un concepto fundamental en la teoría de la probabilidad, que permite calcular la probabilidad de un evento teniendo en cuenta que otro evento ya ha ocurrido. Es especialmente útil en situaciones donde se toman decisiones con base en información previa, como en la planificación financiera o la investigación de mercado. -
La asimetría es la medida que indica la simetría de la distribución de una variable respecto a la media aritmética sin necesidad de hacer la representación gráfica. Los coeficientes de asimetría indican si hay el mismo número de elementos a izquierda y derecha de la media.
Existen tres tipos de curva de distribución según su asimetría:- Asimetría negativa: la cola de la distribución se alarga para valores inferiores.
- Simétrica: hay el mismo número de elementos a izquierda y derecha de la media. En este caso, coinciden la media, la mediana y la moda. La distribución se adapta a la forma de la campana de Gauss o distribución normal.
- Asimetría positiva: la cola de la distribución se alarga (a la derecha) para valores superiores a la media.
La curtosis o apuntalmiento es una medida de forma que mide cuán escarpada o achatada está una curva o distribución.
Este coeficiente indica la cantidad de datos que hay cercanos a la media, de manera que a mayor grado de curtosis más escarpada (o apuntada) será la forma de la curva.
La curtosis se mide promediando la cuarta potencia de la diferencia entre cada elemento del conjunto y la media, dividido entre la desviación elevada también a la cuarta potencia. -
La inferencia estadística es el conjunto de métodos y técnicas que permiten inducir, a partir de la información empírica proporcionada por una muestra, cuál es el comportamiento de una determinada población con un riesgo de error medible en términos de probabilidad.El intervalo de confianza describe la variabilidad entre la medida obtenida en un estudio y la medida real de la población (el valor real). Corresponde a un rango de valores, cuya distribución es normal y en el cual se encuentra, con alta probabilidad, el valor real de una determinada variable. Esta «alta probabilidad» se ha establecido por consenso en 95%. Así, un intervalo de confianza de 95% nos indica que dentro del rango dado se encuentra el valor real de un parámetro con 95% de certeza.
-
La distribución de Bernoulli es una distribución discreta que está relacionada con muchas distribuciones, tales como la distribución binomial, geométrica y binomial negativa. Representa el resultado de un solo ensayo. Las secuencias de ensayos de Bernoulli independientes generan las demás distribuciones: la binomial modela el número de éxitos en n ensayos, la geométrica modela el número de fallas antes del primer éxito y la binomial negativa modela el número de fallas antes del éxito xésimo.Piense en los ensayos como repeticiones de un experimento. La letra n denota el número de ensayos. Solo hay dos resultados posibles, llamados "éxito" y "fracaso", para cada ensayo. La letra p denota la probabilidad de éxito y q la de fracaso. Se cumple que p + q = 1.
-
Sea X(t) el número de ocurrencias del evento con el tiempo (el proceso); entonces X(t) consiste en funciones de valores enteros no-decrecientes. La probabilidad de que sucedan exactamente k eventos en el tiempo t es:
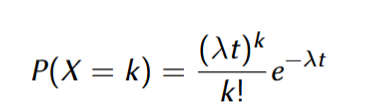 El teorema del límite central implica que si el tamaño de la muestra n es grande, la distribución de la suma parcial Yn es aproximadamente normal, con media nμ y varianza nσ². De forma equivalente, la media muestral es aproximadamente normal, con media μ y varianza σ²/n.
El teorema del límite central implica que si el tamaño de la muestra n es grande, la distribución de la suma parcial Yn es aproximadamente normal, con media nμ y varianza nσ². De forma equivalente, la media muestral es aproximadamente normal, con media μ y varianza σ²/n. -
La prueba de hipótesis trata de probar si la conjetura es verdadera o falsa, y luego contrastar con lo que los datos demuestran. Podemos tener 4 posibles resultados:
1. La decisión es no rechazar H0 cuando H0 es verdadera (decisión correcta).
2. La decisión es rechazar H0 cuando H0 es verdadera (error tipo I).
3. La decisión es no rechazar H0 cuando H0 es falsa (error tipo II).
4. La decisión es rechazar H0 cuando H0 es falsa (decisión correcta, cuya probabilidad se denomina potencia de la prueba).
α = P(error tipo I) = rechazar H0 cuando H0 es verdadera.
β = P(error tipo II) = no rechazar H0 cuando H0 es falsa.
α y β deben ser lo más pequeños posible, ya que son probabilidades de error. La potencia de la prueba es 1 - β, y lo ideal es que sea lo más cercana posible a 1. Aumentar el tamaño de la muestra puede incrementar la potencia.En la curva de densidad, mientras más alejado está un valor de la media, menor es su probabilidad. Si un estadístico como t-calculado cae fuera de los límites definidos por alfa (por ejemplo, 0.025 y 0.975), hay solo un 2.5% de probabilidad de que la muestra pertenezca a la población, por lo tanto, se rechaza H0.
El área bajo la curva se divide en dos:
- Área donde H0 es aceptada.
- Área donde H0 es rechazada.
Estas áreas se definen por el valor de alfa, y determinan la zona de rechazo de la hipótesis nula. -
La prueba de Shapiro-Wilk es una prueba estadística que evalúa si una muestra de datos sigue una distribución normal. Es más fiable en conjuntos de datos pequeños y devuelve un valor p para determinar si se cumple el supuesto de normalidad. En Python, suele emitir una advertencia para tamaños de muestra superiores a 5000.
La prueba de Shapiro-Wilk comprueba si una muestra proviene de una distribución normal. Su hipótesis nula presupone normalidad; un valor p bajo indica una desviación de dicho supuesto.
Los científicos de datos suelen comprobar si los datos siguen una distribución normal. Un ejemplo es la comprobación de normalidad de los residuos de la regresión lineal para utilizar correctamente la prueba F. Una forma de comprobar la normalidad es mediante la prueba de Shapiro-Wilk.La prueba de Ansari-Bradley es una prueba no paramétrica que se utiliza para comparar varianzas entre dos o más muestras, lo que la convierte en una herramienta valiosa en el campo de la estadística para analizar escalas de varianza sin asumir una distribución normal. Esta prueba es particularmente útil cuando no se puede cumplir el supuesto de normalidad, lo cual suele ocurrir con datos del mundo real. Sirve como alternativa a pruebas clásicas como la prueba F para ANOVA, que requieren normalidad y varianzas iguales entre los grupos.
1. Estadístico de prueba: El estadístico de prueba de la prueba de Ansari-Bradley se basa en la clasificación de las desviaciones absolutas con respecto a la mediana. Este método de clasificación garantiza que la prueba sea menos sensible a los valores atípicos, que podrían influir en los resultados de las pruebas paramétricas.
2. Prueba de hipótesis: La hipótesis nula (H0) postula que las varianzas son iguales en todos los grupos, mientras que la hipótesis alternativa (H1) sugiere que al menos un grupo tiene una varianza diferente.
3. Supuestos: Si bien no asume normalidad, la prueba requiere que las distribuciones tengan la misma forma y que las muestras sean independientes. -
La homocedasticidad es un término estadístico que se refiere a la suposición o condición en la que los errores (o residuos) de un modelo de regresión tienen varianza constante con respecto a la variable independiente o predictor. Es decir, la dispersión de los errores en torno a la línea de regresión es uniforme para todos los valores de la variable independiente. Como hemos indicado anteriormente, la homocedasticidad nos dice que los residuos de un modelo (la diferencia entre la realidad y lo que predice el modelo), tienen una varianza constante.La heterocedasticidad se define como uno de los problemas que pueden presentar los modelos de regresión lineal, cuando las varianzas de sus perturbaciones o errores no son constantes para todas las observaciones de la muestra. Los modelos de regresión lineal presentarán problemas de heterocedasticidad cuando los datos que utilizan provengan de poblaciones heterogéneas con varianzas distintas.
-
Cuando creamos un modelo de regresión múltiple asumimos que las variables seleccionadas no tienen una relación entre sí. Esta es una de las premisas para que el modelo funcione adecuadamente. El problema que se presenta es que, como mencionamos, un modelo de regresión múltiple no es más que varios modelos de regresión simple. Pero cuando las variables predictoras están relacionadas entre sí, el modelo tiene problemas para dilucidar qué efecto está causando cada una de estas variables, dado que ambas pueden representar el mismo efecto.El sobreajuste es un error de modelado, es decir, que el modelo va a tener problemas en sus predicciones. El problema se suscita cuando el modelo ha sido entrenado con una gran cantidad de variables, lo que hace que su recta (curva de regresión) pase por encima o muy cerca de todas las observaciones. En otras palabras, sería un modelo perfecto para predecir las observaciones, pero esto conlleva a que el modelo también haya capturado el ruido de cada variable. Por lo tanto, nuevas observaciones tendrán una mala predicción. Lo que se requiere es que la recta (curva) de regresión sea más genérica.
-
La distribución ji cuadrado es una familia de distribuciones. Cada distribución se define por los grados de libertad. (Los grados de libertad se comentan en mayor detalle en las páginas sobre la prueba de bondad de ajuste y la prueba de independencia). En la siguiente figura se muestran tres distribuciones ji cuadrado diferentes, con distintos grados de libertad.La prueba Chi-cuadrado es una prueba de hipótesis utilizada para determinar si existe una relación entre dos variables categóricas. La prueba Chi-cuadrado comprueba si las frecuencias que se dan en la muestra difieren significativamente de las frecuencias que cabría esperar. Así, se comparan las frecuencias observadas con las esperadas y se examinan sus desviaciones.
-
El algoritmo k vecinos más cercanos (KNN) es un clasificador de aprendizaje supervisado no paramétrico que utiliza la proximidad para hacer clasificaciones o predicciones sobre la agrupación de un punto de datos individual. Es uno de los clasificadores de clasificación y regresión más populares y sencillos que se utilizan en machine learning hoy en día.
Aunque el algoritmo KNN se puede usar para problemas de regresión o clasificación, se suele utilizar como un algoritmo de clasificación, que parte de la suposición de que se pueden encontrar puntos similares cerca unos de otros.
Para los problemas de clasificación, la etiqueta de clase se asigna en función de la mayoría de votos, es decir, se utiliza la etiqueta que se representa con más frecuencia en torno a un punto de datos determinado. Si bien esto se considera técnicamente “votación por pluralidad”, en la literatura se utiliza más comúnmente el término “voto por mayoría”. La distinción entre estas terminologías es que la “votación por mayoría” técnicamente requiere una mayoría superior al 50 %, lo que funciona principalmente cuando solo hay dos categorías. Cuando tiene varias clases, por ejemplo cuatro categorías, no necesita necesariamente el 50 % de los votos para llegar a una conclusión sobre una clase; puede asignar una etiqueta de clase con un voto superior al 25 %.Caret es una abreviatura de Entrenamiento de Clasificación y Regresión, es un paquete de R que contiene funciones para optimizar el proceso de entrenamiento de modelos para problemas complejos de regresión y clasificación. El paquete utiliza varios paquetes de R, pero intenta no cargarlos todos al iniciar el paquete (al eliminar las dependencias formales de los paquetes, el tiempo de inicio del paquete se puede reducir considerablemente). El campo "sugerencias" del paquete incluye 31 paquetes.
Caret carga los paquetes según sea necesario y asume que están instalados. Si falta un paquete de modelado, se le solicita que lo instale. -
En estadística, la verosimilitud no es una probabilidad, sino una función de los parámetros del modelo que representa la probabilidad de observar un conjunto específico de datos, dados dichos parámetros. Mide la eficacia con la que una hipótesis o un modelo explica los datos observados, tratando estos como fijos y los parámetros del modelo como variables, lo cual es inverso al funcionamiento de la probabilidad condicional. La función de verosimilitud se utiliza para encontrar los valores más probables de los parámetros que generaron los datos mediante técnicas como la Estimación de Máxima Verosimilitud (EMV).
Estimación de máxima verosimilitud (MLE): este es un método común donde el objetivo es encontrar el valor del parámetro que maximiza la función de verosimilitud, encontrando así el valor del parámetro que hace que los datos observados sean más probables.Los grados de libertad son la combinación del número de observaciones de un conjunto de datos que varían de manera aleatoria e independiente menos las observaciones que están condicionadas a estos valores arbitrarios. En otras palabras, los grados de libertad son el número de observaciones puramente libres (que pueden variar) cuando estimamos los parámetros. -
El remuestreo es una técnica estadística computacionalmente intensiva en la que se extraen (generan) múltiples muestras nuevas a partir de la muestra de datos o de la población inferida por esta. Se calculan entonces ciertas estadísticas (o estimaciones) de interés (p. ej., la mediana muestral) para cada una de estas nuevas muestras, y los múltiples valores calculados resultantes se analizan para investigar y estimar diversas propiedades (p. ej., la distribución muestral, el error, el sesgo) de las estadísticas.
Para qué sirve:
El enfoque clásico para determinar las diversas propiedades de una estimación particular implica suposiciones sobre la distribución poblacional subyacente. Por ejemplo, las características de la media de una muestra aleatoria son particularmente fáciles de calcular si dicha muestra proviene de la familia de distribuciones normales.
Sin embargo, existen muchas situaciones en las que la determinación de las propiedades de un estimador no es tan sencilla, por ejemplo, el sesgo y el error estándar. Existen varios tipos de remuestreo: permutación, validación cruzada, jackknife y bootstrap.La prueba de razón de verosimilitud (LRT) es una prueba estadística que mide la bondad de ajuste entre dos modelos. Se compara un modelo relativamente más complejo con uno más simple para determinar si se ajusta significativamente mejor a un conjunto de datos. De ser así, los parámetros adicionales del modelo más complejo suelen utilizarse en análisis posteriores.
La LRT solo es válida si se utiliza para comparar modelos anidados jerárquicamente, es decir, cuando el modelo más complejo difiere del modelo simple únicamente por la adición de uno o más parámetros. Añadir parámetros adicionales siempre resultará en una puntuación de verosimilitud más alta. Sin embargo, llega un punto en que añadir parámetros adicionales ya no se justifica en términos de una mejora significativa en el ajuste de un modelo a un conjunto de datos.
-