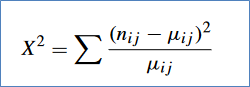-
Introducción
Mostrar más Mostrar menosIntroducción
Queridos participantes,
¡Bienvenidos a esta emocionante aventura digital! Nos entusiasma ser parte de este viaje de aprendizaje, en el que descubrirán nuevas herramientas, adquirirán valiosos conocimientos y desarrollarán habilidades que les acompañarán a lo largo de su trayectoria.
Les invitamos a familiarizarse con la plataforma, conocer el curso y participar activamente.
¡Estamos aquí para apoyarlos en cada paso de este proceso!
¡Mucho éxito en este inicio!
El equipo de PUCE Virtual
-
-
-
-
Vencimiento: martes, 4 de noviembre de 2025, 23:00
Mostrar más-
-
1.0. Terminología Básica
En primer lugar, empecemos indicando que es estadística: Existen múltiples definiciones de la estadística, posiblemente una por cada autor, a continuación, veremos algunas de las mejores definiciones:
- La estadística es la ciencia que estudia cómo debe emplearse la información y cómo dar una guía de acción en situaciones prácticas que entrañan incertidumbre., la cual implica su recolección, clasificación, síntesis, organización, análisis e interpretación, para la toma de decisiones frente a la incertidumbre. Gutiérrez 1998
- La estadística es la rama del conocimiento humano que tiene como objeto el estudio de ciertos métodos inductivos aplicables a fenómenos susceptibles de expresión cuantitativa. (López, 2020)
De estas definiciones podemos extraer los siguientes detalles:
De acuerdo con Gutierrez, (2007), debemos notar que hace referencia a la “incertidumbre”. Esto es correcto, aunque, contrario a lo que se piensa, la estadística no es una ciencia matemática cuyos resultados sean siempre exactos. En realidad, las operaciones estadísticas nos muestran valores dentro de un rango. No podemos asegurar cuál es el valor real, pero sabemos que estará dentro de un intervalo determinado.
Notaremos que la estadística abarca desde funciones que tiene que ver con la recolección de la información, su tratamiento y análisis de lo que nos está mostrando.
Por último, de acuerdo con López (2020), la estadística es una ciencia de carácter inductivo, lo que significa que se basa en los datos para tomar decisiones, a diferencia de los estudios deductivos, en los cuales se conoce de antemano lo que se intenta demostrar.
Existen tres ramas (o si se quiere tres etapas) de la estadística, cada una comprende una serie de técnicas y funciones que permiten contestar las siguientes preguntas:
¿Qué pasó? ¿Qué está pasando?
¿Qué pasará si seguimos de la misma manera en el futuro?
¿Qué podría pasar si se alteran las condiciones del negocio?
En esta clase, trataremos de responder la primera pregunta. El conjunto de métodos y procedimientos que nos ayudan a contestarla se denomina estadística descriptiva.
Estadística Descriptiva: Es la rama de las matemáticas que recolecta, presenta y caracteriza un conjunto de datos (por ejemplo, edad de una población, altura de los estudiantes de una escuela, temperatura en los meses de verano, etc.) con el fin de describir apropiadamente las diversas características de ese conjunto. Por lo tanto, la estadística descriptiva se apoya o trabaja en base a variables que describen un proceso, evento, negocio, una enfermedad, etc.
Puede haber múltiples variables en un caso de estudio y estas variables pueden ser de distinta naturaleza. De la misma manera que el éxito de una aplicación es haber realizado un correcto análisis de las propiedades de los objetos y clases, el éxito de la estadística es haber recolectado todos los factores que afectan al proceso, evento, negocio, etc.
Tipos de Datos
Para iniciar con la estadística descriptiva, es importante mencionar que existen varios tipos de datos. Comúnmente, asociamos la palabra "dato" con una variable numérica, pero esto no siempre es el caso. Existen diversos tipos de datos dentro del análisis estadístico.
Empezaremos por catalogar dos grandes grupos de tipos de datos:
- Variables cuantitativas: Las observaciones se expresan numéricamente. Dentro de esta categoría podemos ubicar algunas variantes:
- Variables continuas: Son aquellas que pueden tomar cualquier valor, con cualquier cantidad de decimales, en algunos casos podrían estar acotadas o dentro de un rango. Ejemplo: π = 3.14159.
- Variables discretas: Pueden tomar determinados valores numéricos únicamente, por ejemplo, la edad de una persona. Un caso particular de esta es la data binaria que solo puede tomar dos valores: Verdadero/Falso.
- Series de Tiempo: Es una subclase de cuantitativa representada por listas o vectores que representan el valor de la variable a través del tiempo, por ejemplo, temperatura de la ciudad durante el año.
- Ratio o Razón: Relación entre dos variables numéricas y generalmente se expresa en términos de porcentajes, por ejemplo, tasa de cambio de una moneda.
- Intervalo: Variables que se hallan dentro de un rango. Esto es muy utilizado por ejemplo en secuencias en R o rangos en Python, ejemplo: secuencia de conteo del 1 al 10, en R representado por la función seq (1::10).
- Variables cualitativas: A este grupo pertenecen las variables que describen características que pueden presentarse en los elementos que conforman el conjunto de datos. En R también se les conoce como variables tipo factor. En esta categoría podemos ubicar los siguientes casos:
- Variables categóricas: Son variables que se consideran clasificadoras o calificadoras, ya que catalogan los elementos en grupos, conjuntos o categorías. Se conocen como dicotómicas aquellas que solo pueden adoptar dos valores diferentes, y como politómicas las que poseen un número de valores mayor a dos.
- Variables nominales: Nombres o clasificaciones que se utilizan para datos en categorías, por ejemplo, país, género, color, que por su naturaleza no pueden ser ordenadas.
- Variables ordinales: Datos que si bien no son numéricos, sí nos dan un sentido de prioridad. Por ejemplo: pequeño, mediano, grande; variables que pueden ser ordenadas.
La siguiente figura explica la clasificación:
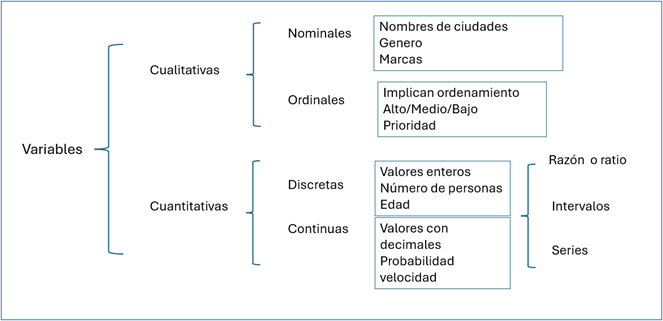
Figura 1: Taxonomía de las variables.
Creación autor: Alfonso Prado. -
1.1 Medidas de tendencia central
Como mencionamos anteriormente, el propósito de la estadística descriptiva es describir los datos. Existen múltiples herramientas para ello. A continuación, exploraremos algunas de las más comunes.
1.1.1 Promedio
Promedio: Es el valor central de un conjunto de datos y nos indica cuál es el valor esperado para una , considerando todas las posibilidades. En R, la función utilizada para calcularlo es mean(), cuya sintaxis y fórmula se describen en la siguiente figura.

Figura 2
Referencia: Función mean sintaxis y fórmula . www.rdocumentation.orgLa función acepta los siguientes argumentos:
- x: representa el vector que contiene los datos.
- trim: Es la fracción (0 a 0.5) de observaciones que se deben recortar de cada extremo de
xantes de calcular la media. . Los valores de recorte que se encuentren fuera de ese rango se toman como el punto final más cercano y es útil en caso de que el dataset tenga valores atípicos. - na.rm: Un valor lógico que indica si los valores NA deben eliminarse antes del cálculo. En R cuando un valor de una variable figura como NA indica que no se ha ingresado dicho valor y es diferente al caso de asumir que su valor es cero o nulo. La importancia de este argumento radica en que cualquier operación que se realiza sobre un vector que contiene al menos un valor NA dará como resultado NA.
Si analizamos la fórmula de la función mean(), veremos que todos los valores tienen un peso igual. Esto podría no ser apropiado en algunos casos. Para esto utilizamos la media ponderada:
Media ponderada:
La media aritmética ponderada es similar a una media aritmética, excepto que en lugar de que cada una de las observaciones contribuyan igualmente al promedio final, algunas contribuyen más que otras. Podemos obtener la media ponderada usando el paquete DescTools. La función y formula se muestran en la figura 3..

Figura 3: Media Ponderada sintaxis y fórmula
Referencia: Media Ponderada sintaxis y fórmula. www.rdocumentation.orgNote que la función es Mean con mayúscula, en R mayúsculas no son igual que minúsculas. Los argumentos son similares a la función mean, excepto que se introduce el argumento weights, que representa los pesos de cada una de la observaciones
- weights: representa los pesos de cada una de las observaciones.
Media geométrica
Esta es un tipo de media que se usa generalmente en ambientes financieros debido a que su resultado es un poco más conservador. Su valor se obtiene mediante la raíz n de la multiplicación de los valores de las observaciones. Existen muchos paquetes que proveen esta funcionalidad, en nuestra clase utilizaremos la función gm() del paquete rob.compositions . Debido a que la multiplicación de los valores de las observaciones puede arrojar valores muy grandes alternativamente se puede calcular como la constante de Euler (e=2.7182) elevado a la potencia de la media de los logaritmos neperianos de la data, de esta forma garantizamos que no se producirá un “overflow” en su cálculo. Su función y fórmula se muestran en la figura 4..

Figura 4: Media geométrica, sintaxis y fórmula
1.1.2 Moda
Moda: Esta función permite calcular el o los valores más repetidos dentro de un conjunto de datos. En lenguaje R, el paquete modeest ofrece diversas funciones para estimar la moda, destacándose entre ellas la función mlv(), la cual retorna un vector numérico con el valor o los valores más frecuentes. Esta función admite varios métodos de estimación, lo que proporciona flexibilidad según las características de los datos analizados. La sintaxis correspondiente se muestra en la Figura 5.
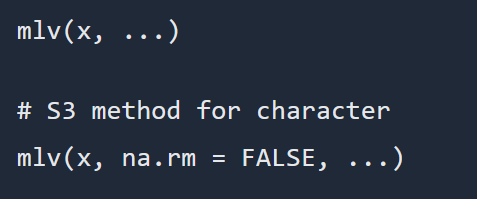
Figura 5: Sintaxis de la función mlv
Referencia: Moda sintaxis y fórmula . www.rdocumentation.org .mlv es una función genérica para estimar la moda de una distribución univariante. Se proporcionan diferentes métodos, el más común es “mfv” que significa el valor más frecuente.
-
1.2 Medidas de dispersión
Se llama dispersión de los datos a la variabilidad que existe entre ellos. Cuando tenemos un set de datos de una variable aleatoria, se podría pensar que estos podrían asumir cualquier valor. Sin embargo, en la realidad, cuando se analiza un fenómeno, los datos tienden a estar más o menos agrupados alrededor de la media. Existen varias funciones que nos permiten cuantificar esta dispersión.
1.2.1 Percentiles
Cuantiles: Los cuantiles nos dan una primera idea de la distribución de los valores. Un cuantil o percentil indica qué porcentaje de los datos se encuentra por debajo de un cierto valor de la variable bajo análisis. Por ejemplo, el cuantil del 50 por ciento es lo mismo que la mediana. R tiene algunas funciones convenientes para ayudar a observar los cuantiles.
La función quantile() puede proporcionarle cualquier cuantil que desee. Para ello, se utiliza el argumento
probscomo un número fraccionario. Por ejemplo, para obtener el cuantil del 20%, se utilizará 0.20 como valor de este argumento. Este argumento también puede recibir un vector como valor, por lo que es posible obtener los cuantiles de 5% y 95% simultáneamente.Es importante mencionar que existen distintos algoritmos para el caso de variables discretas y continuas, y que no todas las herramientas informáticas utilizan el mismo algoritmo. Esto puede ser relevante e incluso desconcertante si se está trabajando con diferentes herramientas a la vez, ya que podrían proporcionar resultados distintos.
Los algoritmos se numeran del 1 al 3 para variables discretas, como fechas o factores ordenados, y del 4 al 9 para variables continuas. El algoritmo se define mediante el argumento type, siendo 7 el valor por defecto.
La figura 6 muestra la sintaxis de la función quantile(), así como las fórmulas aplicables a los distintos métodos.
Aprende más
Para conocer más sobre el tema, puedes leer el siguiente artículo ¡Accede aquí!
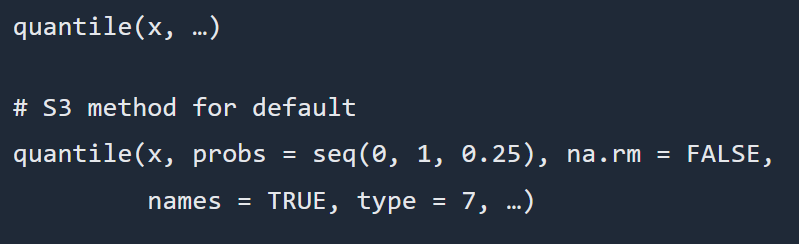
Figura 6: Sintaxis función quantile
Referencia: Quantile sintaxis. www.rdocumentation.org1.2.2 Varianza
Varianza: Es una medida de dispersión que representa la variabilidad de una serie de datos respecto a su media. Una serie de datos podría tomar un número infinito de valores, pero en la práctica, cuando se analiza un parámetro de interés, los datos tienden a estar dentro de un rango más o menos disperso. La varianza indica la medida de esta dispersión.

Figura 7: Función y fórmula de la varianza
Referencia: Varianza sintaxis y fórmula. www.rdocumentation.org1.2.3 Desviación
Desviación estándar: Representa la raíz cuadrada de la varianza. El símbolo σ (sigma) se utiliza frecuentemente para representar la desviación estándar de una población, mientras que s se utiliza para representar la desviación estándar de una muestra.
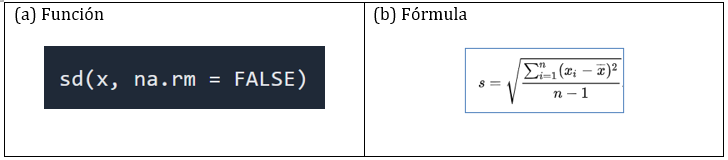
Figura 8: Desviación estándar función y fórmula
Referencia: Desviación estándar función y fórmula. www.rdocumentation.org1.2.4 Cómo visualizar la dispersión de los datos
ggplot2 es un paquete de visualización de datos para el lenguaje R. Es un esquema general para la visualización de datos que divide los gráficos en componentes semánticos en una modalidad de capas. ggplot2 es un paquete mejorado de los gráficos base en R (plot).
Forma parte del paquete Tidyverse, un sistema para la manipulación, exploración y visualización de datos que comparten una filosofía de diseño común. Los paquetes del Tidyverse están destinados a ser usados por estadísticos y científicos de datos. Básicamente, tidyverse trata sobre las conexiones entre las herramientas que hacen posible el flujo de trabajo.
ggplot2 permite generar una gran cantidad de tipos de gráficos. Las gráficas de dispersión son más útiles para mostrar la relación entre dos variables continuas, o cuando una entidad está compuesta por dos valores. Para visualizar la dispersión utilizaremos la función geom_point, cuya sintaxis se muestra en la figura 9.
Información adicional sobre ggplot2, el siguiente enlace describe la operación básica del paquete (enlace).
Aprende más
Para conocer más sobre ggplot2, puedes leer el siguiente artículo ¡Accede aquí!
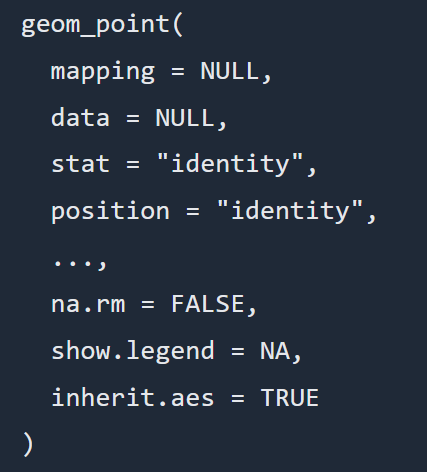
Figura 9
Referencia: Sintaxis de la función geom_point, www.rdocumentation.orgDonde el argumento mapping permite indicar qué variables del dataset son asignadas a cada eje. El argumento data, por supuesto, corresponde al dataframe que contiene los datos. El argumento position permite alterar la posición de las observaciones en situaciones de sobre-trazado, con el fin de mejorar la visualización.
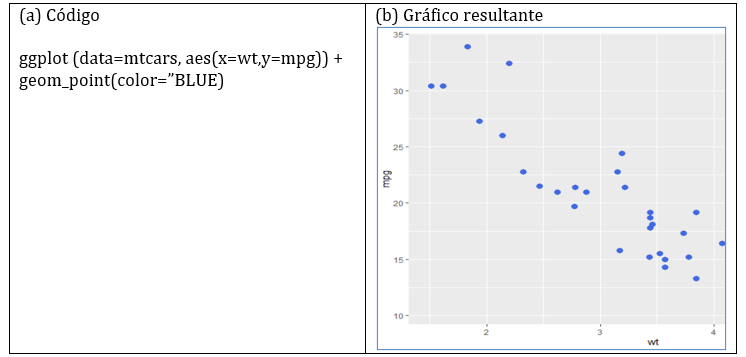
Figura 10: Código y visualización de la dispersión del dataset mtcars
Creación autor: Alfonso PradoProfundiza más
Este recurso te ayudará a enfatizar sobre Diagramas de dispersión ¡Accede aquí!
-
Hacer un envío
-
Hacer intentos: 1
-
-
Introducción
En esta clase, iniciaremos con el estudio de las relaciones entre variables; específicamente, trataremos sobre distintas funciones y algoritmos para medir la correlación y covarianza entre dos o más variables, así como técnicas para visualizar la correlación.
Un tema importante en la estadística es tratar de entender cómo se relacionan las variables entre sí. Para ello, introduciremos los temas de correlaciones, covarianza y causación. Lo anterior estará apoyado por el conocimiento del marco general del lenguaje R y la interfase RStudio, los mismos que se usarán en los laboratorios propuestos y que reforzarán el aprendizaje incorporando algunos enlaces externos. Un tema particular en este caso es la determinación de la existencia de relaciones espurias.
-
Reto #2
2. Relacionamiento de variables
En la clase anterior, revisamos la clasificación de las variables desde el punto de vista de los tipos de datos; es así que mencionamos la distinción entre variables continuas y discretas, o variables nominales y ordinales.
Ahora presentaremos otra clasificación basada en la relación que se observa entre estas variables, en base al concepto de causa-efecto. La idea es entender si una variable es la causante de que otra variable cambie de valor.
Variables Predictoras y de Respuesta
Predictoras (anteriormente llamadas variables independientes) son variables que representan un argumento para obtener un efecto sobre otra variable.
Variables de Respuesta (anteriormente llamadas dependientes) son variables que obtienen su valor en base a variables predictoras.
Para entender mejor el tema imagine la representación de una función matemática en un plano cartesiano Y = f(x), donde la variable Y tomará un valor derivado de la variable X y no al revés.
Por ejemplo, en R tenemos un dataset llamado
mtcars, el cual contiene una decena de variables relacionadas con características de vehículos. Dos de estas características son:disp(que representa el volumen de los cilindros de un vehículo, establecido en centímetros cúbicos) ympg(el rendimiento o millas por galón), y queremos entender qué tipo de relación tiene este par de variables.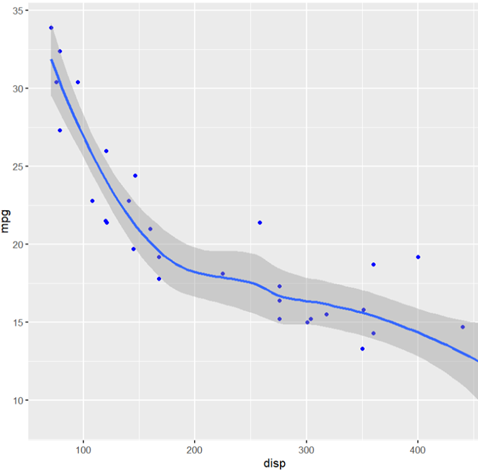
Figura 1: Relación disp vs mpg
Creación de autor: Alfonso PradoDe la Figura 1 notamos que a medida que los cc. del motor aumentan, el rendimiento de consumo de gasolina disminuye.
En estadística, una relación monótona entre dos variables se refiere a un escenario en el que un cambio en una variable generalmente se asocia con un cambio en una dirección específica en otra variable.
Hay dos tipos de relaciones monótonas:
- Monotónica positiva: Cuando el valor de una variable aumenta, el valor de la otra variable tiende a aumentar también.
- Monotónica negativa: Cuando el valor de una variable aumenta, el valor de la otra variable tiende a disminuir.
- No monotónica: Si dos variables generalmente no cambian en la misma dirección, entonces se dice que tienen una relación no monótona.
Cuando analizamos la relación entre dos variables, también es importante distinguir entre un comportamiento lineal y no lineal. En algunos casos, podemos observar que dicha relación es monotónica positiva solo en cierto rango y luego pasa a ser monotónica negativa, o simplemente se estabiliza en cierto valor.
En base a estos dos conceptos podemos establecer las siguientes posibilidades:
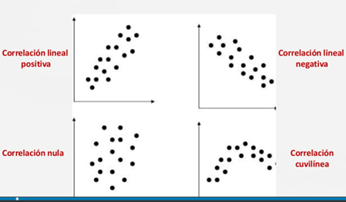
Figura 2: Distintos tipos de correlaciones
-
2.1 Medición de la correlación y covarianza
Una vez que hemos entendido la relación entre dos variables, nos interesa cuantificar qué tan fuerte es dicha relación; para esto, existen distintos métodos para cuantificarla. Estos métodos podemos distinguirlos en dos clases.
PRUEBAS PARAMÉTRICAS Y NO PARAMÉTRICAS
La diferencia principal entre estos dos tipos es su base matemática para el cálculo. Las pruebas paramétricas se basan en el entendimiento de la distribución de las variables. Este concepto lo veremos más adelante en el curso. Por el momento, diremos que las pruebas paramétricas asumen una cierta distribución.
Ventajas de las Pruebas Paramétricas
- Tienen más poder de eficiencia.
- Más sensibles a los rasgos de los datos recolectados.
- Menos posibilidad de errores.
- Dan estimaciones probabilísticas bastante exactas.
2.1.1 Correlación
Para el cálculo de la correlación tenemos las siguientes pruebas:
Correlación de Pearson: mide una dependencia lineal entre dos variables (X, Y). Es una prueba de tipo paramétrica. Se puede usar solo cuando X e Y son de distribución normal (esto lo veremos más adelante).
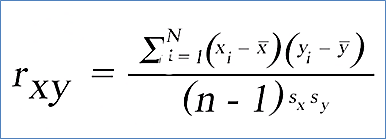
Figura 3: Fórmula de la Correlación de Pearson
Donde:
- ̄X y ̄Y representan la media del vector X y Y respectivamente.
- Sx y Sy representan las desviaciones estándar de X y Y respectivamente.
- n es la cantidad de observaciones.
Correlación de Kendall y Spearman, son coeficientes de correlación basados en rangos (no paramétricos): Las pruebas no paramétricas son aquellas que se encargan de analizar datos que no tienen una distribución particular y se basan en hipótesis, pero los datos no están organizados de forma normal. Aunque tienen algunas limitaciones, cuentan con resultados estadísticos ordenados que facilita su comprensión.
Para el cálculo de la correlación usaremos la función
cor()cuya sintaxis se muestra en la siguiente figura.
Figura 4: Sintaxis de la función cor
Referencia: Sintaxis de la función, www.rdocumentation.orgRetorna el coeficiente de correlación.
Es importante mencionar que
cor()puede tomar 2 vectores (X y Y) o un dataframe completo que puede tener múltiples columnas, por lo tanto, si la data es muy extensa su resultado será una matriz de correlaciones entre todos los vectores deldata.frame.Esta matriz tiene las siguientes características:
- La matriz es simétrica, la correlación entre a y b es la misma que entre b y a.
- Los valores de la correlación varían entre -1 y 1; el signo indica si la relación es monotónica negativa o positiva, y el valor absoluto indica qué tan fuerte es la relación.
- La diagonal es siempre 1 (una variable siempre se correlaciona consigo misma).
Es recomendable limitar las columnas que intervienen mediante “subsetting”, es decir, seleccionando un subconjunto de columnas de interés.
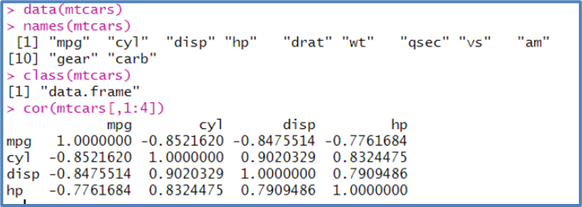
Tabla 1: Matriz de correlación en el dataset mtcars
Creación de autor: Alfonso PradoCuando la matriz es pequeña como en la tabla anterior, analizar las relaciones es simple, pero cuando se tiene decenas o centenas de variables se torna difícil. En este caso recurrimos a la visualización.
Por ejemplo, utilizando el dataset
economics, este contiene las siguientes columnas:- Pce: Gastos de consumo personal
- Pop: Población total, en miles
- Psavert: Tasa de ahorro personal
- Uempmed: Duración media del desempleo, en semanas
- Unemploy: Número de desempleados en miles
Utilizando
ggplot, podemos crear un mosaico cuyos colores representan la fuerza de la correlación. Colores fuertes representan una correlación alta, y colores neutros como el blanco indican una correlación nula. Estos gráficos son conocidos como .Existen muchas formas de crear estos correlogramas. El siguiente enlace cubre algunas posibilidades.
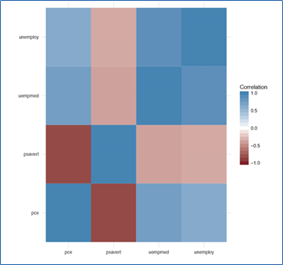
Figura 5: Diagrama calor de la correlación del dataset economics
Creación de autor: Alfonso Prado2.1.2 Covarianza
Hemos visto que la correlación indica la relación que existe entre dos variables; es decir, si una de ellas (la variable predictora) cambia, la variable de respuesta también cambiará, ya sea hacia arriba o hacia abajo.
Por otro lado, la covarianza es un valor que indica el grado de variación conjunta de dos variables aleatorias respecto a sus medias. Es el dato básico para determinar si existe una dependencia entre ambas variables y es esencial para estimar otros parámetros fundamentales, como el coeficiente de correlación lineal o la recta de regresión. También ayuda a entender si estas dos variables están relacionadas de alguna forma.
Retorna un valor que puede ser positivo (si se mueven juntas), negativo (si se mueven en direcciones opuestas), o nulo (si no se mueven juntas de manera apreciable). Existen varios métodos (algoritmos) para su cálculo.
En otras palabras, la covarianza trata de encontrar la relación entre dos variables predictoras. Se asume que hay una variable predictora que provoca cambios entre las variables de respuesta. Queremos encontrar la relación entre estas dos variables predictoras.
La función para determinar la covarianza y su fórmula de cálculo se puede ver en la siguiente gráfica:

Figura 6: Sintaxis de la función cov (a) y su fórmula de cálculo (b)
Referencia: Sintaxis de la función, www.rdocumentation.org2.1.3 Correlación con variables categóricas
Hasta el momento, hemos visto cómo cuantificar la relación entre variables cuantitativas numéricas, pero, como mencionamos antes, estas no son el único tipo de variables que la estadística puede procesar. Otro caso importante es el de las variables nominales. Para este tipo de datos, utilizamos tablas de contingencia.
De acuerdo con Agresti A. (2013), el análisis de datos categóricos se basa típicamente en tablas de contingencia de dos o más dimensiones, tabulando la frecuencia de ocurrencia de niveles de datos nominales y/o ordinales. Una tabla de contingencia es una herramienta que permite organizar datos categóricos en filas y columnas, mostrando la frecuencia de ocurrencia de cada combinación de valores. Esta tabla nos permite medir la interacción entre dos variables y obtener información valiosa para comprender mejor los resultados de una investigación.
Por ejemplo, trabajando con el dataset Oncho, este dataset describe la cantidad de personas encuestadas para saber si padecen de esta enfermedad (onchocercosis). Tenemos una variable que indica si está infectada la persona, pero también contiene otras variables como el área (Savannah o Rainforest), sex (el género masculino o femenino) y grupo de edad (0-20, 20-39, 40+). Todas estas variables son tipo categórico.
En R, estas variables pueden ser convertidas al tipo factor. Un factor no es nada más que una variable categórica que permite agrupación y las distintas opciones de cada variable toman el nombre de niveles del factor. Por ejemplo, para el factor “área” hay 2 niveles: Savannah o Rainforest.
Con estos datos podemos crear una tabla de contingencia que nos permita medir la relación entre estas variables en términos de frecuencia de ocurrencia en el dataset, por ejemplo, no infectados en la Savannah tenemos 267 personas mientras que infectadas en la misma área 281.
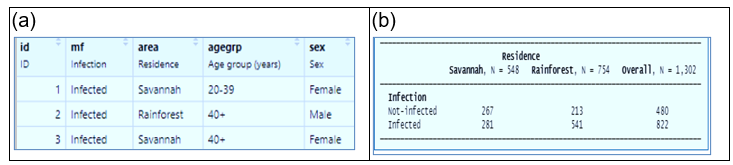
Figura 7:Dataset (a) y tabla de contingencia (b)
Debemos notar que la cantidad de observaciones de un nivel nominal no va a ser necesariamente la misma de otro nivel. Por ejemplo, la cantidad de encuestados hombres (Male) no es igual a las mujeres (Female).
En algunos campos de investigación como la bioestadística se estila crear la tabla con nombres genéricos como Exposure y Outcome, donde las filas (Exp+ y Exp-) indican haber estado sujeto a un “tratamiento” y las columnas conocidas como Out+ y Out- haber desarrollado un efecto o no. En nuestro dataset Oncho, el área sería el “tratamiento” y
mfel “efecto”.Los datos de frecuencia de la tabla por sí solos no indican mayor cosa, por lo tanto, la tabla debe ser procesada a fin de obtener algunos estadísticos que nos indiquen si existe una relación entre un par de variables. El proceso de análisis va a ser diferente si la tabla es de 2x2 (dos filas y dos columnas) o de más filas, como por ejemplo si analizamos la variable “agegrp”.
Para el caso de variables dicotómicas (esto es, variables que solo tienen dos posibles niveles) la función
epi.2by2()nos ayuda a obtener los estadísticos necesarios, pero para tablas más grandes la funciónchisq.test()sería la apropiada. Analizaremos estas funciones más adelante en el curso.Tratamiento de tablas de contingencia
Describe distintas funciones utilizadas en el análisis enlace -
2.2 Causación
Las medidas de correlación y covarianza nos indican cómo cambia una variable cuando la otra variable cambia. Es decir, solo nos indican cómo se mueven las variables en el dataset, pero no necesariamente nos indican que una variable causa a la otra variable.
Ejemplo: Usted dispone de un dataset que contiene población de una ciudad, el consumo de carne y el consumo de pescado en la ciudad. Existe una correlación directa entre las dos últimas variables y la población. Esto es correcto porque se asume que mientras más grande es la población de una ciudad, hay más consumo.
Pero, si se efectúa una correlación entre consumo de pescado y consumo de carne también encontrará correlación directa. ¿Significa esto que el consumo de carne hace que se consuma más pescado? Por supuesto que no. En este caso existe correlación, pero no existe causación, es decir, el consumo de carne no produce que se consuma más pescado. Por lo tanto, diremos que la causación implica correlación, pero la correlación no implica causación.
Análisis de Correlación
Describe varias funciones para análisis de correlación y causaciónAprende más
Para conocer más sobre el tema, puedes leer el siguiente artículo ¡Accede aquí!
2.2.1 Diseño de Experimentos
De acuerdo con Mendiburu F, Yaseen M. (2020), el propósito del diseño de experimentos (DoE) es poder obtener en forma segura la relación causa-efecto entre dos variables. Por ejemplo: saber si un cierto medicamento ayudó (o no) en la recuperación del paciente. Para aseverar que lo anterior es verdadero ciertas consideraciones deben cumplirse.
Asociación
El primer criterio para establecer un efecto causal es una asociación observada entre la variable predictora y de respuesta. Generalmente esto se logra mediante un análisis de correlación. Por otro lado, debemos garantizar que existe la relación tiene un ordenamiento en el tiempo. Se debe asegurar que la variación de la variable predictora se produjo antes del tiempo de la variación de la variable de respuesta.
Detección de asociaciones espurias
El segundo criterio es que esta relación no sea espuria, definimos como espuria a una relación que es ficticia o fraudulenta. Muchas veces nos topamos con la existencia de una tercera variable que en realidad afecta a las dos primeras. Este tipo de variable se las conoce como “confounding” (que produce confusión).
La siguiente figura ilustra la relación entre la edad del paciente y el riesgo de enfermedad coronaria. En principio parecería que la edad es un factor, pero la variable confounding sería el ejercicio.

Figura 8: Correlación vs Causación en enfermedad coronaria
Creación de autor: Alfonso PradoPara garantizar que la relación no sea espuria debemos cumplir las siguientes condiciones:
- Dos grupos de comparación (en el caso más simple, un grupo experimental y un grupo de control), para establecer asociación.
- Variación en la variable independiente se produce antes del cambio en la variable dependiente, para establecer el orden temporal.
- Asignación aleatoria a los dos (o más) grupos de comparación, para establecer que la relación no es espuria.
-
Hacer un envío
-
Hacer intentos: 1
-
-
-
Ruta Académica - RDA2 - T1 Tarea
-
Ruta Académica - RDA2 - T2 Tarea
-
-
-
Bienvenidos a PUCE CAFÉ: Un Espacio Abierto para la Participación y Reflexión
PUCE CAFÉ es un espacio diseñado para fomentar la conversación abierta y el intercambio de ideas entre los participantes del aula virtual. Aquí, les invitamos a reflexionar sobre los temas abordados, plantear preguntas, y compartir inquietudes sobre los contenidos trabajados.
Este es el lugar perfecto para aclarar dudas, profundizar en conceptos y mejorar la comprensión de los temas. Pueden discutir aspectos como la incorporación de multimedia en Moodle, la organización y categorización de contenidos, y las mejores prácticas para mejorar la accesibilidad y la experiencia de usuario en entornos de aprendizaje virtual.
Recuerden, no existen preguntas incorrectas; cada aporte, ya sea una pregunta o comentario, contribuye a enriquecer la experiencia de aprendizaje colectiva. Los animamos a participar activamente, ya que, además de contar con nuestro apoyo, también pueden aprender de los conocimientos y experiencias compartidas por sus compañeros.
¡Esperamos sus preguntas y comentarios para seguir construyendo juntos este proceso de aprendizaje!
-
-
-
-
CORRELOGRAMAEs un gráfico que permite apreciar las autocorrelaciones r₁, r₂, ..., rₖ mediante el cual se identifican si los datos de una serie de tiempo tienen las siguientes características: estacionalidad, aleatoriedad, tendencia y estacionariedad.PRUEBA CHI CUADRADODe acuerdo con Ramírez-Alan (2016), “El test Χ² considera la hipótesis nula (H₀) de que las variables son independientes. Si esto es verdad, la frecuencia de ocurrencia debería estar dada por la cantidad de casos totales multiplicada por la probabilidad esperada”.
En el ejemplo anterior, si la probabilidad de compra es igual para los 3 niveles socioeconómicos (πᵢⱼ = 33%), entonces si se han vendido 1000 ítems, estos deberían estar distribuidos en las 3 categorías (n*πᵢⱼ = 1000*0.33), valor conocido como μᵢⱼ.
Pero si Hₐ está en lo correcto, va a existir una diferencia entre la frecuencia observada (ηᵢⱼ) y la esperada (μᵢⱼ), indicando que existe algún fenómeno por detrás que influencia la frecuencia observada. La prueba Χ² calcula esta diferencia de la siguiente forma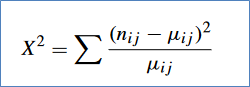
-
PMFUna función de probabilidad o función de masa de probabilidad es una función que devuelve la probabilidad de que una variable aleatoria discreta sea exactamente igual a algún valor. Es una función que asocia a cada punto de su espacio muestral X la probabilidad de que esta lo asuma.Proceso de PoissonSea X(t) el número de ocurrencias del evento con el tiempo (el proceso); entonces X(t) consiste en funciones de valores enteros no-decrecientes. La probabilidad de que sucedan exactamente k eventos en el tiempo t es:
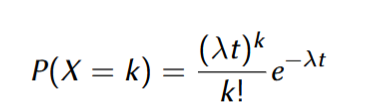
-
ERRORES TIPO I Y TIPO IIEn la teoría de decisiones, es el error TIPO I es el que se comete al rechazar la hipótesis nula H 0, cuando es verdadera.
El error tipo II, es el error que se comete al aceptar la hipótesis nula H 0 cuando es falsa. REGIÓN DE ACEPTACIÓN y RECHAZOEs la región formada por el conjunto de valores con los cuales decidimos aceptar la hipótesis nula, el área de rechazo conocida también como región crítica, está formada por el conjunto de valores con los cuales se rechaza la hipótesis nula.
REGIÓN DE ACEPTACIÓN y RECHAZOEs la región formada por el conjunto de valores con los cuales decidimos aceptar la hipótesis nula, el área de rechazo conocida también como región crítica, está formada por el conjunto de valores con los cuales se rechaza la hipótesis nula. -
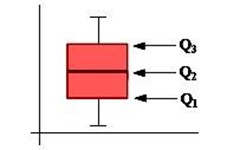
COEFICIENTE DE DETERMINACIÓN AJUSTADO r^2El R cuadrado ajustado es una versión modificada del R cuadrado que tiene en cuenta los predictores que no son significativos en un modelo de regresión. En otras palabras, el R cuadrado ajustado muestra si la adición de predictores adicionales mejora o no un modelo de regresión. El coeficiente de determinación mide la proximidad del ajuste de la ecuación de regresión de la muestra a los valores observados de la variable dependiente.DIAGRAMA DE CAJASConocido también como BOXPLOT. Es un importante gráfico del análisis exploratorio de datos. Al igual que el histograma, permite tener una idea visual de la distribución de los datos. Permite determinar si hay simetría, ver el grado de variabilidad existente y detectar los "outliers" (datos muy diferentes al conjunto de información), es decir la existencia de posibles datos discordantes. Además, el Boxplot es bien útil para comparar grupos. Es un diagrama que muestra la distancia en que se encuentran los datos y cómo están distribuidos equitativamente.
 SUMA DE CUADRADOS DE RESIDUOSLa suma de cuadrados residuales , también conocida como la suma de los residuos al cuadrado o la suma de la estimación al cuadrado de los errores , es la suma de los cuadrados de los residuos (desviaciones predichas de los valores empíricos reales de los datos) . Es una medida de la discrepancia entre los datos y un modelo de estimación. Un pequeño SSRes indica un ajuste ajustado del modelo a los datos. Se utiliza como criterio de optimización en la selección de parámetros y la selección de modelos.
SUMA DE CUADRADOS DE RESIDUOSLa suma de cuadrados residuales , también conocida como la suma de los residuos al cuadrado o la suma de la estimación al cuadrado de los errores , es la suma de los cuadrados de los residuos (desviaciones predichas de los valores empíricos reales de los datos) . Es una medida de la discrepancia entre los datos y un modelo de estimación. Un pequeño SSRes indica un ajuste ajustado del modelo a los datos. Se utiliza como criterio de optimización en la selección de parámetros y la selección de modelos.
En el contexto de ANOVA este estadístico se llama SST
Dado por la fórmula siguiente: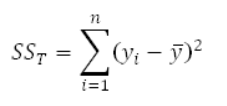
-
Distribución Chi-cuadradoLa distribución ji cuadrado es una familia de distribuciones. Cada distribución se define por los grados de libertad. (Los grados de libertad se comentan en mayor detalle en las páginas sobre la prueba de bondad de ajuste y la prueba de independencia). En la siguiente figura se muestran tres distribuciones ji cuadrado diferentes, con distintos grados de libertad.
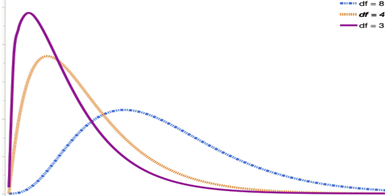 Prueba de Chi cuadradoLa prueba Chi-cuadrado es una prueba de hipótesis utilizada para determinar si existe una relación entre dos variables categóricas. La prueba Chi-cuadrado comprueba si las frecuencias que se dan en la muestra difieren significativamente de las frecuencias que cabría esperar. Así, se comparan las frecuencias observadas con las esperadas y se examinan sus desviaciones.
Prueba de Chi cuadradoLa prueba Chi-cuadrado es una prueba de hipótesis utilizada para determinar si existe una relación entre dos variables categóricas. La prueba Chi-cuadrado comprueba si las frecuencias que se dan en la muestra difieren significativamente de las frecuencias que cabría esperar. Así, se comparan las frecuencias observadas con las esperadas y se examinan sus desviaciones.
-
-
-